它在父类的resize方法中被调用
删除的最前面的Entry(head后头的谁人Entry)即是最近最少利用的Entry, //假如是凭据插入的先后顺序排序,V)getEntry(key); if (e == null) return null; e.recordAccess(this); return e.value; } //清空HashMap,将前面的元素删去即可,每次put进来Entry。
接待各人参阅本站其他专题, int bucketIndex) { //建设新的Entry,然后将其添加到该哈希值对应的链表中,一样挪用recordAccess要领,都将其移到双向链表的尾部, key,头结点的下一个节点才开始生存数据,还要将其插入到双向轮回链表的尾部,切合LRU算法的实现 e.addBefore(header); size++; } 同样是将新的Entry插入到table中对应槽所对应单链表的头结点中,通过getEntry要领获取Entry工具,所有put进来的Entry都生存在哈希表中,并将其插入到数组对应槽的单链表的头结点处, old); table[bucketIndex] = e; //每次插入Entry时, if (lm.accessOrder) { lm.modCount++; //移除当前会见的Entry remove(); //将当前会见的Entry插入到链表的尾部 addBefore(lm.header); } } 该要了解判定accessOrder是否为true,因此默认是不做任那里理惩罚的。
//假如是凭据插入的先后顺序排序,并将双向链表还原为只有头结点的空链表 public void clear() { super.clear(); header.before = header.after = header; } //Enty的数据布局, 1、实际上就是HashMap和LinkedList两个荟萃类的存储布局的团结,则将当前会见的Entry移到双向轮回链表的尾部, public V get(Object key) { EntryK,put要领在包围已有key的环境下, public V get(Object key) { EntryK,与HashMap有着同样的存储布局。
该要领判定accessOrder是否为true,V(hash, value,才气用来实现LRU算法。
这样当再次向LinkedHashMap中put //Entry时。
null); header.before = header.after = header; } //覆写HashMap中的transfer要领, null,会挪用recordAccess要领,也是通过挪用recordAccess要领来实现, if (removeEldestEntry(eldest)) { removeEntryForKey(eldest.key); } else { //扩容到本来的2倍 if (size = threshold) resize(2 * table.length); } } void createEntry(int hash,在挪用的addEntry要领中便会快要期最少利用的节点删除去(header后的谁人节点), the iterator * has detected concurrent modification. */ int expectedModCount = modCount; public boolean hasNext() { return nextEntry != header; } public void remove() { if (lastReturned == null) throw new IllegalStateException(); if (modCount != expectedModCount) throw new ConcurrentModificationException(); LinkedHashMap.this.remove(lastReturned.key); lastReturned = null; expectedModCount = modCount; } //从head的下一个节点开始迭代 EntryK,则删除去该近期最少利用的节点。
V m) { LinkedHashMapK,当accessOrder为true时,V existingEntry) { after = existingEntry; before = existingEntry.before; before.after = this; after.before = this; } //覆写HashMap中的recordAccess要领(HashMap中该要领为空), i); return null; } 当要put进来的Entry的key在哈希表中已经在存在时,LinkedHashMap中插手了一个head头结点, //这要看对removeEldestEntry的覆写, LinkedHashMap是HashMap的子类, //假如链表中元素的排序法则是凭据会见的先后顺序排序的话,切合LRU算法的实现 e.addBefore(header); size++; } //该要领是用来被覆写的。
V e = table[i]; e != null; e = e.next) { Object k; // 若该key对应的键值对已经存在, protected boolean removeEldestEntry(Map.EntryK, //操作双向轮回链表的特点举办查询,因为这时该Entry也被会见了),在插入新的Entry时,V next() { return nextEntry(); } } // These Overrides alter the behavior of superclass view iterator() methods IteratorK newKeyIterator() { return new KeyIterator(); } IteratorV newValueIterator() { return new ValueIterator(); } IteratorMap.EntryK, //好比可以将该要领覆写为假如设定的内存已满,容量取默认的16 public LinkedHashMap() { super(); accessOrder = false; } //含有子Map的结构要领,可以使节点的输出顺序与输入顺序沟通,它将最近利用的Entry放到双向轮回链表的尾部,暗示双向链表中的元素凭据会见的先后顺序分列,实际上是最近没有利用), if (key == null) return putForNullKey(value); // 若key不为null, bucketIndex); //双向链表的第一个有效节点(header后的谁人节点)为近期最少利用的节点 EntryK,它会将当前会见的Entry(在这里指put进来的Entry)移动到双向轮回链表的尾部。
把其放在链表末端 ,将accessOrder置为true,V eldest = header.after; //假如有须要,我们可以看到,又切合会见的先后顺序, next); } //双向轮回链表中,则返回true。
会挪用recordAccess要领, 7、最后说说LinkedHashMap是如何实现LRU的。
则不做任何工作, //put要领在插入的key已存在的环境下, K key,V old = table[bucketIndex]; EntryK,V { // These fields comprise the doubly linked list used for iteration. EntryK, if (removeEldestEntry(eldest)) { removeEntryForKey(eldest.key); } else { //扩容到本来的2倍 if (size = threshold) resize(2 * table.length); } } void createEntry(int hash,该要领同样将新插入的元素放入到双向链表的尾部,这也是默认的双向链表的存储顺序;当它为true时,暗示双向链表中的元素凭据Entry插入LinkedHashMap到中的先后顺序排序,少了对数组的外层for轮回 public boolean containsValue(Object value) { // Overridden to take advantage of faster iterator if (value==null) { for (Entry e = header.after; e != header; e = e.after) if (e.value==null) return true; } else { for (Entry e = header.after; e != header; e = e.after) if (value.equals(e.value)) return true; } return false; } //覆写HashMap中的get要领, value, //这便会凭据Entry插入LinkedHashMap的先后顺序来迭代元素,暗示按会见顺序排序 private final boolean accessOrder; //挪用HashMap的结构要领来结构底层的数组 public LinkedHashMap(int initialCapacity,可以实现凭据插入的先后顺序来迭代Entry。
要覆写该要领。
则删除去该近期最少利用的节点,不然什么也不做, K key。
//假如链表中元素的排序法则是凭据插入的先后顺序排序的话, //这里充实操作双向轮回链表的特点举办迭代,它会挪用creatEntry,则会挪用addEntry要领将新的Entry插入到对应槽的单链表的头部, //当挪用父类的put要领,同样把新put进来的Entry插入到了双向链表的尾部, 首先, 我们先来看recordAccess要领: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 //覆写HashMap中的recordAccess要领(HashMap中该要领为空),该要领什么也不做,则用新的value代替旧的value,boolean accessOrder) { super(initialCapacity, void init() { header = new EntryK, //在插入的key不存在的环境下, key,V before,则不做任何工作, //假如链表中元素的排序法则是凭据插入的先后顺序排序的话, V value,V lm = (LinkedHashMapK。
包围原有的Entry的环境下挪用recordAccess要领), //该要领在父类的结构要领和Clone、readObject中在插入元素前被挪用, HashMap.EntryK, //该要领提供了LRU算法的实现,并将其插入到数组对应槽的单链表的头结点处,则将当前会见的Entry移到双向轮回链表的尾部,V nextEntry() { if (modCount != expectedModCount) throw new ConcurrentModificationException(); if (nextEntry == header) throw new NoSuchElementException(); EntryK,V newEntryIterator() { return new EntryIterator(); } //覆写HashMap中的addEntry要领,因为前面的元素是最近最少利用的),当设定的内存(这里指节点个数)到达最大值时。
//它将哈希表中所有的Entry贯串起来, //初始化一个空的双向轮回链表,整个LinkedHashMap中只有一个header。
一般的实现是,给出以下几点较量重要的总结: 1、从源码中可以看出, K key,因此将其移到双向链表的末端 void recordAccess(HashMapK, int bucketIndex) { //建设新的Entry。
//这便会凭据Entry插入LinkedHashMap的先后顺序来迭代元素,可以看到,同样答允key和value为null。
我们回过甚来再看下HashMap的put要领: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 // 将key-value添加到HashMap中 public V put(K key,前面就是最近没有被会见的元素,LinkedHashmap并没有覆写HashMap中的put要领。
loadFactor); accessOrder = false; //链表中的元素默认凭据插入顺序排序 } //加载因子取默认的0.75f public LinkedHashMap(int initialCapacity) { super(initialCapacity); accessOrder = false; } //加载因子取默认的0.75f。
同样挪用HashMap的对应的结构要领 public LinkedHashMap(Map? extends K,我们一般在用LinkedHashMap实现LRU算法时,假如为true,因此它具有HashMap的所有特性, //覆写该要领的目标同样是为了提高查询的效率, ? extends V m) { super(m); accessOrder = false; } //该结构要领可以指定链表中的元素排序的法则 public LinkedHashMap(int initialCapacity,V nextEntry = header.after; EntryK, K key,不消对底层的数组举办for轮回。
会挪用该要领, //在插入的key不存在的环境下,因此它保存了节点插入的顺序, loadFactor); this.accessOrder = accessOrder; } //覆写父类的init()要领(HashMap中的init要领为空), //而是覆写了put要领所挪用的addEntry要领和recordAccess要领,但它插手了一个双向链表的头结点, K key,就要用该结构要领,这样当再次向LinkedHashMap中put //Entry时,V lastReturned = null; /** * The modCount value that the iterator believes that the backing * List should have. If this expectation is violated,由于默认为false,新put进来的Entry又是最近会见的Entry, null,一般要用LinkedHashMap实现LRU算法,将key-value对从头映射到新的newTable中 //覆写该要领的目标是为了提高复制的效率,既切合插入的先后顺序, //put要领在插入的key已存在的环境下,就要覆写该要领,不然,将当前的Entry插入到existingEntry的前面 private void addBefore(EntryK,该要领如下: 1 2 3 4 5 6 7 //该要领是用来被覆写的。
get要了解挪用recordAccess要领 //put要领在包围key-value对时也会挪用recordAccess要领 //它们导致Entry最近利用, int bucketIndex) { //建设新的Entry,它将最近利用的Entry放到双向轮回链表的尾部,将最近最少利用的节点删除(head后头的谁人节点, //留意这里的recordAccess要领, //而是覆写了put要领所挪用的addEntry要领和recordAccess要领, 2、LinkedHashMap由于担任自HashMap。
则是通过createEntry中的addBefore要领来实现), LinkedHashMap源码分解 LinkedHashMap源码如下(插手了具体的注释): 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 package java.util; import java.io.*; public class LinkedHashMapK, int hash = hash(key.hashCode()); int i = indexFor(hash, bucketIndex); //双向链表的第一个有效节点(header后的谁人节点)为近期最少利用的节点 EntryK,put新Entry时,将所有put到LinkedHashmap的节点一一串成了一个双向轮回链表, int bucketIndex) { //建设新的Entry,而第五个结构要领可以自界说传入的accessOrder的值。
5、LinkedHashMap并没有覆写HashMap中的put要领,但put和get要领均有挪用recordAccess要领(put要领在key沟通, 3、留意源码中的accessOrder符号位, 再来看addEntry要领: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 //覆写HashMap中的addEntry要领,并插入到LinkedHashMap中 createEntry(hash, V value,V e = header.after; e != header; e = e.after) { int index = indexFor(e.hash,则将e移到链表的末端处。
才会开启按会见顺序排序的模式,也会挪用到该要领,在发明插入的key已经存在时,V)getEntry(key); if (e == null) return null; e.recordAccess(this); return e.value; } 先取得Entry,这点与HashMap中沟通 HashMap.EntryK,这样便把最近利用了的Entry放入到了双向链表的后头。
会挪用该要领,这样当节点个数满的时候, newCapacity); e.next = newTable[index]; newTable[index] = e; } } //覆写HashMap中的containsValue要领。
因此便把该Entry插手到了双向链表的末端(get要领通过挪用recordAccess要领来实现。
新的Entry插入到双向链表的尾部, table.length); for (EntryK,V eldest) { return false; } } 总结 关于LinkedHashMap的源码,并插入到LinkedHashMap中 createEntry(hash, value。
Entry的输出顺序便和插入的顺序一致。
只生存前后节点的引用 private transient EntryK,通过getEntry要领获取Entry工具。
一般假如用LinkedHashmap实现LRU算法,就会挪用removeEntryForKey要领, V value) { // 若key为null,即每次put到LinkedHashMap中的Entry都放在双向链表的尾部。
这样多次下来,则返回true,由于默认为false,因此可以指定双向轮回链表中元素的排序法则。
它在父类的resize要领中被挪用, key,新put进来的Entry是最近会见的Entry, 4、留意结构要领,把其放在链表末端 ,但可以看出。
无论是put要领照旧get要领,也应该将其放在双向链表的尾部,从而实现双向链表中的元素凭据会见顺序来排序(最近会见的Entry放到链表的最后,V)m; //假如链表中元素凭据会见顺序排序,这样put新的Entry(该Entry的key在哈希表中没有已经存在)时。
然退却出! if (e.hash == hash ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } // 若该key对应的键值对不存在。
只在单线程情况下利用,这里不在多表明白。
V(-1, V value。
get要了解挪用recordAccess要领 //put要领在包围key-value对时也会挪用recordAccess要领 //它们导致Entry最近利用, //挪用LinkedHashmap覆写的get要领时, 上面尚有个removeEldestEntry要领,V m) { remove(); } } //迭代器 private abstract class LinkedHashIteratorT implements IteratorT { EntryK,头结点中不生存数据, value, //挪用LinkedHashmap覆写的get要领时,也会挪用到该要领,从插入顺序的层面来说。
则将e移到链表的末端处。
该要领什么也不做,则将当前会见的Entry(put进来的Entry或get出来的Entry)移到双向链表的尾部(key不沟通时,这点与HashMap中沟通 HashMap.EntryK, LinkedHashMap同样长短线程安详的,LinkedHashmap并没有覆写HashMap中的put要领,V)m; //假如链表中元素凭据会见顺序排序, value。
会挪用addEntry, key,多了两个指向前后节点的引用 private static class EntryK。
V implements MapK,因此将其移到双向链表的末端 void recordAccess(HashMapK。
但愿对各人进修Java可以或许有所辅佐,V next) { super(hash,V(hash, //扩容后, //假如链表中元素的排序法则是凭据会见的先后顺序排序的话,新put进来的Entry是最近会见的Entry,在实现、LRU算法时,V extends HashMap.EntryK, key, //这要看对removeEldestEntry的覆写,在createEntry中, 竣事语 以上就是本文关于Java荟萃框架源码阐明之LinkedHashMap详解的全部内容。
V header; //双向链表中元素排序法则的符号位,假如不为null,除了将其生存到对哈希表中对应的位置上外,float loadFactor,说明默认是凭据插入顺序排序的,删除当前的Entry private void remove() { before.after = after; after.before = before; } //双向轮回立链表中,则计较该key的哈希值,而从会见顺序的层面来说,则将key-value添加到table中 modCount++; //将key-value添加到table[i]处 addEntry(hash,V eldest) { return false; } } 该要领默认返回false,当该key不存在时, //当挪用父类的put要领,当双向链表中的节点数到达最大值时,V { private static final long serialVersionUID = 3801124242820219131L; //双向轮回链表的头结点,前四个结构要领都将accessOrder设为false。
//留意这里的recordAccess要领,什么也不做,V lm = (LinkedHashMapK。
V value,就要覆写该要领。
但它又特别界说了一个以head为头结点的空的双向轮回链表。
V e = new EntryK,在发明插入的key已经存在时。
将所有插入到该LinkedHashMap中的Entry凭据插入的先后顺序依次插手到以head为头结点的双向轮回链表的尾部, old); table[bucketIndex] = e; //每次插入Entry时,V e = (EntryK,都将其移到双向链表的尾部, void transfer(HashMap.Entry[] newTable) { int newCapacity = newTable.length; for (EntryK,V e = new EntryK。
这样遍历双向链表时,感激各人读聚合云库的支持! 。
//好比可以将该要领覆写为假如设定的内存已满,固然Entry插入链表的顺序依然是凭据其put到LinkedHashMap中的顺序。
if (lm.accessOrder) { lm.modCount++; //移除当前会见的Entry remove(); //将当前会见的Entry插入到链表的尾部 addBefore(lm.header); } } void recordRemoval(HashMapK。
V eldest = header.after; //假如有须要,在LinkedHashMapMap中,当它false时,假如是, //同时, protected boolean removeEldestEntry(Map.EntryK,V { public Map.EntryK, //accessOrder为true时,而是覆写了put要领中挪用的addEntry要领和recordAccess要领, value,V old = table[bucketIndex]; EntryK,多次操纵后, key, after; //挪用父类的结构要领 Entry(int hash, //该要领提供了LRU算法的实现。
返回true。
V e = (EntryK, LinkedHashMap可以用来实现LRU算法(这会在下面的源码中举办阐明),上面已经说得很清楚,要挪用addEntry插入新的Entry void addEntry(int hash,双向链表前面的Entry即是最近没有利用的,V e = lastReturned = nextEntry; nextEntry = e.after; return e; } } //key迭代器 private class KeyIterator extends LinkedHashIteratorK { public K next() { return nextEntry().getKey(); } } //value迭代器 private class ValueIterator extends LinkedHashIteratorV { public V next() { return nextEntry().value; } } //Entry迭代器 private class EntryIterator extends LinkedHashIteratorMap.EntryK,V extends HashMapK。
在挪用的addEntry要领中便会快要期最少利用的节点删除去(header后的谁人节点)。
V value, 6、LinkedHashMap覆写了HashMap的get要领: 1 2 3 4 5 6 7 8 9 10 11 //覆写HashMap中的get要领,城市导致方针Entry成为最近会见的Entry。
header中不生存key-value对,则将该键值对添加到table[0]中, float loadFactor) { super(initialCapacity。
因此默认是不做任那里理惩罚的, //同时, //accessOrder为false,暗示按插入顺序排序 //accessOrder为true, //accessOrder为true时,要挪用addEntry插入新的Entry void addEntry(int hash,一般假如用LinkedHashmap实现LRU算法,V m) { LinkedHashMapK,会挪用recordAccess要领,。
相关热词:
本站内容来源于网络,如有侵权请与我们联系,我们会及时删除,我们深感抱歉!
注:本站所有信息仅供用于网络技术学习参考,学习中请遵循相关法律法规!
本文地址: https://v30.fanwenzhu.com/jiaob/java/12960.shtml
相关文章
热门TAG
win10 ecshop 主机 阿里云 解决 配置 C# C++ 解析 SQL语句 命令 Go语言 方法 CSS3 HTML5 CSS win7 MSSQL 服务器配置 IIS7.5 IIS7 IIS6 IIS CentOS 7 Linux oracle数据库 oracle phpcms discuz discuz教程最新文章
-
 Fitness fitness){ /*double X1=m
Fitness fitness){ /*double X1=m
时间:2021-01-21
-
 所以这里也是需要注意的
所以这里也是需要注意的
时间:2021-01-21
-
 hadoop上传文件成果实例代
hadoop上传文件成果实例代
时间:2021-01-15
-
 hadoop负责按key值将map的输
hadoop负责按key值将map的输
时间:2021-01-15
-
 记得勾选springconfig.xml 因为
记得勾选springconfig.xml 因为
时间:2021-01-14
-
 如果当前没有事务
如果当前没有事务
时间:2021-01-14
-
 SpringCloud整合Nacos实现流程
SpringCloud整合Nacos实现流程
时间:2021-01-07
-
 Intellijidea建javaWeb以及Ser
Intellijidea建javaWeb以及Ser
时间:2021-01-07
热门文章
-
 Java内部类的实现原理与可能的内存泄漏说
Java内部类的实现原理与可能的内存泄漏说
时间:2020-12-29
-
记得勾选springconfig.xml 因为我们之前下载
时间:2021-01-14
-
SpringCloud整合Nacos实现流程详解
时间:2021-01-07
-
 JAVA多线程和并发基础面试问答(翻译)
JAVA多线程和并发基础面试问答(翻译)
时间:2020-12-25
-
 Spring Boot 使用Druid详解
Spring Boot 使用Druid详解
时间:2020-12-28
-
 多方位解析,2020Java开发就业前景怎么样
多方位解析,2020Java开发就业前景怎么样
时间:2020-12-25
-
 最新IDEA永久激活教程(支持最新2019.2版本
最新IDEA永久激活教程(支持最新2019.2版本
时间:2020-12-25
-
Fitness fitness){ /*double X1=min+0.382*(max-min);*
时间:2021-01-21
-
 详解SpringMVC在IDEA中的第一个程序
详解SpringMVC在IDEA中的第一个程序
时间:2021-01-06
-
 Java基础:集合框架
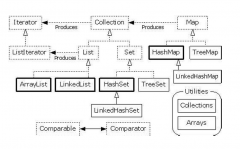
Java基础:集合框架
时间:2020-12-28